《阿里巴巴服务注册中心产品ConfigServer 10年技术发展回顾》
作者:阿里巴巴高级技术专家,许真恩(慕义)
文章概要:本文简单描述了Eureka1.0存在的架构问题,Eureka2.0设想的架构。详细回顾了阿里巴巴的服务注册中心ConfigServer产品从2008年建设元年至今经历的关键架构演进。通过这个文章你会对基于AP模式的注册中心在技术发展过程中将会碰到的问题有所感知。
Eureka1.0架构存在的问题
Eureka作为Netflix公司力推和SpringCloud微服务标配的注册中心开源解决方案,其Eureka 2.0 (Discontinued)的消息在社区引起了不小的骚动;其实早在2015年社区就已经放出了2.0架构的升级设想,但是3年的时间过去,等到的确是Discontinued的消息,虽然2.0的代码在github的主页上也已经放出,但是告诫用户要自行承担当中的使用风险。我想不会有人真的把2.0直接投入到生产中使用。
对于为什么要做Eureka2.0,其官方的wiki中的Why Eureka 2.0和Eureka 2.0 Improvements做了如下的说明
- Only support homogenous client views: Eureka servers only expects the client to always get the entire registry and does not allow to get specific applications/VIP addresses. This imposes a memory limitation on all clients registering with Eureka, even if they need a very small subset of the Eureka’s registry.
- Only supports scheduled updates: Eureka client follows a poll model to fetch updates from the server routinely. This imposes an overhead on the client of doing a scheduled call to the server, even if there are no changes and also delays the updates by the poll interval.
- Replication algorithm limits scalability: Eureka follows a broadcast replication model i.e. all the servers replicate data and heartbeats to all the peers. This is simple and effective for the data set that eureka contains however replication is implemented by relaying all the HTTP calls that a server receives as is to all the peers. This limits scalability as every node has to withstand the entire write load on eureka.
Although Eureka 2.0 provides a more richer feature set, the above limitations are the major driving factors for the changes proposed in this version. Based on the above motivations, Eureka 2.0 achieves the following improvements:
- Interest based subscription model for registry data: A client of Eureka is able to select a part of the instance registry in which it is interested in and the eureka server only sends information about that part of the registry. Eg: A client can say I am only interested in application “WebFarm” and then the server will only send information about WebFarm instances. Eureka server provides various selection criterions and a way to update this interest set dynamically.
- Push model from the server for any changes to the interest set: Instead of the current pull model from the client, Eureka servers pushes updates for changes to the interest set, to the client.
- Optimized replication: As Eureka 1.0, Eureka 2.0 also follows a broadcast replication model i.e. every node replicates data to all other nodes. However, the replication algorithm is much more optimized eliminating the need of sending heartbeats for every instance in the registry. This drastically reduce the replication traffic and achieves much higher scalability.
- Auto-scaled Eureka servers: Eureka 2.0 divides the read (discovery of data) and write (registration) concerns into separate clusters. Since, the write load is predictable (proportional to the number of instances in a region), the write cluster is pre-scaled. On the other hand, read load is unpredictable (proportional to subscriptions from clients) and hence the read farm is auto-scaled.
- Audit log: Eureka 2.0 provides an elaborate audit log for any change done to the registry. This helps Eureka owners as well as users to get insight into debugging the state of individual application instances as exists in Eureka. The audit log by default is persisted to a log file, but different persistent storages can be plugged-in.
- Dashboard: Eureka 2.0 provides a rich dashboard (as opposed to very rudimentary dashboard of Eureka 1.0) with insights into Eureka internals with respect to registry views, server health, subscription state, audit log, etc.
简单翻译总结,也就是Eureka1.0的架构主要存在如下的不足:
- 订阅端拿到的是服务的全量的地址:这个对于客户端的内存是一个比较大的消耗,特别在多数据中心部署的情况下,某个数据中心的订阅端往往只需要同数据中心的服务提供端即可。
- pull模式:客户端采用周期性向服务端主动pull服务数据的模式(也就是客户端轮训的方式),这个方式存在实时性不足以及无谓的拉取性能消耗的问题。
- 一致性协议:Eureka集群的多副本的一致性协议采用类似“异步多写”的AP协议,每一个server都会把本地接收到的写请求(register/heartbeat/unregister/update)发送给组成集群的其他所有的机器(Eureka称之为peer),特别是hearbeat报文是周期性持续不断的在client->server->all peers之间传送;这样的一致性算法,导致了如下问题
- 每一台Server都需要存储全量的服务数据,Server的内存明显会成为瓶颈。
- 当订阅者却来越多的时候,需要扩容Eureka集群来提高读的能力,但是扩容的同时会导致每台server需要承担更多的写请求,扩容的效果不明显。
- 组成Eureka集群的所有server都需要采用相同的物理配置,并且只能通过不断的提高配置来容纳更多的服务数据
Eureka2.0主要就是为了解决上述问题而提出的,主要包含了如下的改进和增强
- 数据推送从pull走向push模式,并且实现更小粒度的服务地址按需订阅的功能。
- 读写分离:写集群相对稳定,无需经常扩容;读集群可以按需扩容以提高数据推送能力。
- 新增审计日志的功能和功能更丰富的Dashboard。
Eureka1.0版本存在的问题以及Eureka2.0架构设想和阿里巴巴内部的同类产品ConfigServer所经历的阶段非常相似(甚至Eureka2.0如果真的落地后存在的问题,阿里巴巴早已经发现并且已经解决),下面我带着你来回顾一下我们所经历过的。
阿里巴巴服务注册中心ConfigServer技术发现路线
阿里巴巴早在2008就开始了服务化的进程,在那个时候就就已经自研出服务发现解决方案(内部产品名叫ConfigServer)。
当2012年9月1号Eureka放出第一个1.1.2版本的时候,我们把ConfigServer和Eureka进行了深度的对比,希望能够从Eureka找到一些借鉴来解决当时的ConfigServer发展过程中碰到的问题(后面会提到);然而事与愿违,我们已经发现Eureka1.x架构存在比较严重的扩展性和实时性的问题(正如上面所描述的),这些问题ConfigServer当时的版本也大同小异的存在,我们在2012年底对ConfigServer的架构进行了升级来解决这些问题。
当2015年Eureka社区放出2.0架构升级的声音的时候,我们同样第一时间查看了2.0的目标架构设计,我们惊奇的发现Eureka的这个新的架构同2012年底ConfigServer的架构非常相似,当时一方面感慨“英雄所见略同”,另一方也有些失望,因为ConfigServer2012年的架构早就无法满足阿里巴巴内部的发展诉求了。
下面我从头回顾一下,阿里巴巴的ConfigServer的技术发展过程中的几个里程碑事件。
2008年,无ConfigServer的时代
借助用硬件负载设备F5提供的vip功能,服务提供方只提供vip和域名信息,调用方通过域名方式调用,所有请求和流量都走F5设备。
遇到的问题:
- 负载不均衡:对于长连接场景,F5不能提供较好的负载均衡能力。如服务提供方发布的场景,最后一批发布的机器,基本上不能被分配到流量。需要在发布完成后,PE手工去断开所有连接,重新触发连接级别的负载均衡。
- 流量瓶颈:所有的请求都走F5设备,共享资源,流量很容易会打满网卡,会造成应用之间的相互影响。
- 单点故障:F5设备故障之后,所有远程调用会被终止,导致大面积瘫痪。
2008年,ConfigServer单机版V1.0
单机版定义和实现了服务发现的关键的模型设计(包括服务发布,服务订阅,健康检查,数据变更主动推送,这个模型至今仍然适用),应用通过内嵌SDK的方式接入实现服务的发布和订阅;这个版本很重要的一个设计决策就是服务数据变更到底是pull还是push的模式,我们从最初就确定必须采用push的模式来保证数据变更时的推送实时性(Eureka1.x的架构采用的是pull的模式)
当时,HSF和Notify就是采用单机版的ConfigServer来完成服务的发现和topic的发现。单机版的ConfigServer和HSF、Notify配合,采用服务发现的技术,让请求通过端到端的方式流动,避免产生流量瓶颈和单点故障。ConfigServer可以动态的将服务地址推送到客户端,服务调用者可以知道所有提供此服务的机器,每个请求都可以通过随机或者轮询的方式选择服务端,做到请求级别的负载均衡。这个版本已经能很好的解决F5设备不能解决的三个问题。
但是单机版本的问题也非常明显,不具备良好的容灾性;
2009年初,ConfigServer单机版V1.5
单机版的ConfigServer所面临的问题就是当ConfigServer在发布/升级的时候,如果应用刚好也在发布,这个时候会导致订阅客户端拿不到服务地址的数据,影响服务的调用;所以当时我们在SDK中加入了本地的磁盘缓存的功能,应用在拿到服务端推送的数据的时候,会先写入本地磁盘,然后再更新内存数据;当应用重启的时候,优先从本地磁盘获取服务数据;通过这样的方式解耦了ConfigServer和应用发布的互相依赖;这个方式沿用至今。(我很惊讶,Eureka1.x的版本至今仍然没有实现客户端磁盘缓存的功能,难道Eureka集群可以保持100%的SLA吗?)
2009年7月,ConfigServer集群版本V2.0
ConfigServer的集群版本跟普通的应用有一些区别:普通的应用通过服务拆分后,已经属于无状态型,本身已经具备良好的可扩展性,单机变集群只是代码多部署几台;ConfigServer是有状态的,内存中的服务信息就是数据状态,如果要支持集群部署,这些数据要不做分片,要不做全量同步;由于分片的方案并没有真正解决数据高可用的问题(分片方案还需要考虑对应的failover方案),同时复杂度较高;所以当时我们选择了单机存储全量服务数据全量的方案。为了简化数据同步的逻辑,服务端使用客户端模式同步:服务端收到客户端请求后,通过客户端的方式将此请求转发给集群中的其他的ConfigServer,做到同步的效果,每一台ConfigServer都有全量的服务数据。
这个架构同Eureka1.x的架构惊人的相似,所以很明显的Eureka1.x存在的问题我们也存在;当时的缓解的办法是我们的ConfigServer集群全部采用高配物理来部署。
2010年底,ConfigServer集群版V2.5
基于客户端模式在集群间同步服务数据的方案渐渐无以为继了,特别是每次应用在发布的时候产生了大量的服务发布和数据推送,服务器的网卡经常被打满,同时cmsgc也非常频繁;我们对数据同步的方案进行了升级,去除了基于客户端的同步模式,采用了批量的基于长连接级别的数据同步+周期性的renew的方案来保证数据的一致性(这个同步方案当时还申请了国家专利);这个版本还对cpu和内存做了重点优化,包括同步任务的合并,推送任务的合并,推送数据的压缩,优化数据结构等;
这个版本是ConfigServer历史上一个比较稳定的里程碑版本。
但是随着2009年天猫独创的双十一大促活动横空出世,服务数量剧增,应用发布时候ConfigServer集群又开始了大面积的抖动,还是体现在内存和网卡的吃紧,甚至渐渐到了fullgc的边缘;为了提高数据推送能力,需要对集群进行扩容,但是扩容的同时又会导致每台服务器的写能力下降,我们的架构到了“按下葫芦浮起瓢”的瓶颈。
2012年底,ConfigServer集群版V3.0
在2011年双十一之前我们完成了V3架构的落地,类似Eureka2.0所设计的读写分离的方案,我们把ConfigServer集群拆分成session和data两个集群,客户端分片的把服务数据注册到session集群中,session集群会把数据异步的写到data集群,data集群完成服务数据的聚合后,把压缩好的服务数据推送到session层缓存下来,客户端可以直接从session层订阅到所需要的服务数据;这个分层架构中,session是分片存储部分的服务数据的(我们设计了failover方案),data存储的是全量服务数据(天生具备failover能力);
data集群相对比较稳定,不需要经常扩容;session集群可以根据数据推送的需求很方便的扩容(这个思路和Eureka2.0所描述的思路是一致的);session的扩容不会给data集群带来压力的增加。session集群我们采用低配的虚拟机即可满足需求,data由于存储是全量的数据我们仍然采用了相对高配的物理机(但是同V2.5相比,对物理机的性能要求已经答复下降)
这个版本也是ConfigServer历史上一个划时代的稳定的大版本。
2014年,ConfigServer集群版V3.5
2013年,阿里巴巴开始落地了异地多活方案,从一个IDC渐渐往多个IDC跨越,随之而来的对流量的精细化管控要求越来越高(比如服务的同机房调用,服务流量的调拨以支持灰度能力等),基于这个背景ConfigServer引入了服务元数据的概念,支持对服务和IP进行元数据的打标来满足各种各样的服务分组诉求。
2017年,ConfigServer集群版V4.0
V3版本可见的一个架构的问题就是data集群是存储全量的服务数据的,这个随着服务数的与日俱增一定会走到升级物理机配置也无法解决问题的情况(我们当时已经在生产使用了G1的垃圾回收算法),所以我们继续对架构进行升级,基于V3的架构进行升级其实并不复杂;session层的设计保持不变,我们把data进行分片,每一个分片同样按照集群的方式部署以支持failover的能力;
| ConfigServer | Eureka | |
|---|---|---|
| 2008年 | V1.0:单机版,定义了服务发现的领域模型 | |
| 2009年初 | V1.5:应用和ConfigServer集群发布解耦 | |
| 2009年7月 | V2.0:基于客户端模式同步数据,支持集群部署 | |
| 2010年底 | V2.5:优化集群间数据同步模式,申请国家专利。 | |
| 2012年9月1号 | Eureka1.0正式开源 | |
| 2012年底 | V3.0:支持session和data分层部署 | |
| 2014年 | V3.5:支持异地多活等细分场景 | |
| 2015年 | Eureka2.0架构升级方案公布 | |
| 2017年 | V4.0:支持data分片能力 | |
| 2018年7月 | Eureka2.0架构升级宣布停止 |
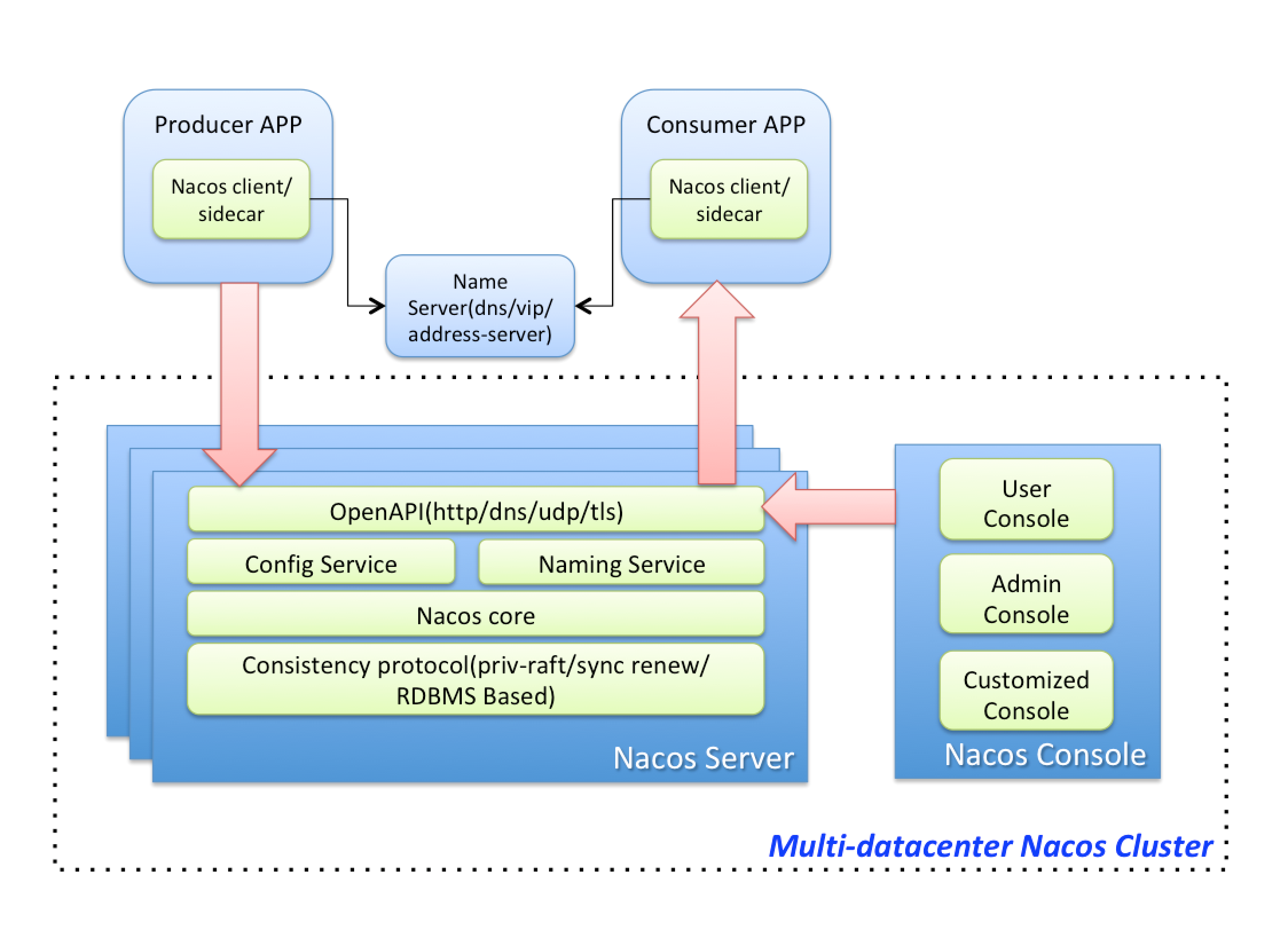
Nacos
作为同属于AP类型的注册中心,Eureka和ConfigServer发展过程中所面临的诸多问题有很大的相似性,但是阿里巴巴这些年业务的跨越式发展,每年翻番的服务规模,不断的给ConfigServer的技术架构演进带来更高的要求和挑战,我们有更多的机会在生产环境发现和解决一个个问题的过程中,做架构的一代代升级。我们正在计划通过开源的手段把我们这些年在生产环境上的实践经验通过Nacos(链接)产品贡献给社区,一方面能够助力和满足同行们在微服务落地过程当中对工业级注册中心的诉求,另一方面也希望通过开源社区及开源生态的协同发展给ConfigServer带来更多的可能性。
炎炎夏日,在Eureka 2.0 (Discontinued) 即将结束的时候,在同样的云原生时代,Nacos却正在迎来新生,技术演进和变迁的趣味莫过于此。
Nacos将努力继承Eureka未竟的遗志,扛着AP系注册中心的旗帜继续前行,不同的是Nacos更关注DNS-based Service Discovery以及与Kubernetes体系的融会贯通。
我们看不透未来,却仍将与同行们一起上下求索,砥砺前行。
最后附上Nacos的架构图。