Summarize
This 1.3.0 is implanted to a great extent, involving the modification of two large modules and the addition of a core module
- nacos-core module modification
- nacos
- nacos internal event mechanism
- nacos consistency protocol layer
- nacos-config module modification
- Add embedded distributed data storage components
- Separation of embedded storage and external storage
- Simple operation and maintenance of embedded storage
- Add nacos-consistency module
- Unified abstraction for AP protocol and CP protocol
System parameters changes
Updates
| core | nacos.watch-file.max-dirs | JVM parameter | Maximum number of monitored directories |
|---|
| nacos.core.notify.ring-buffer-size | JVM parameter | Quick notification of the maximum length of the queue |
| nacos.core.notify.share-buffer-size | JVM parameter | The maximum length of the slow notification queue |
| nacos.core.member.fail-access-cnt | JVM parameter.properties | Maximum number of failed visits to cluster member nodes |
| nacos.core.address-server.retry | JVM parameter、application.properties | Address server addressing mode, first start request retry times |
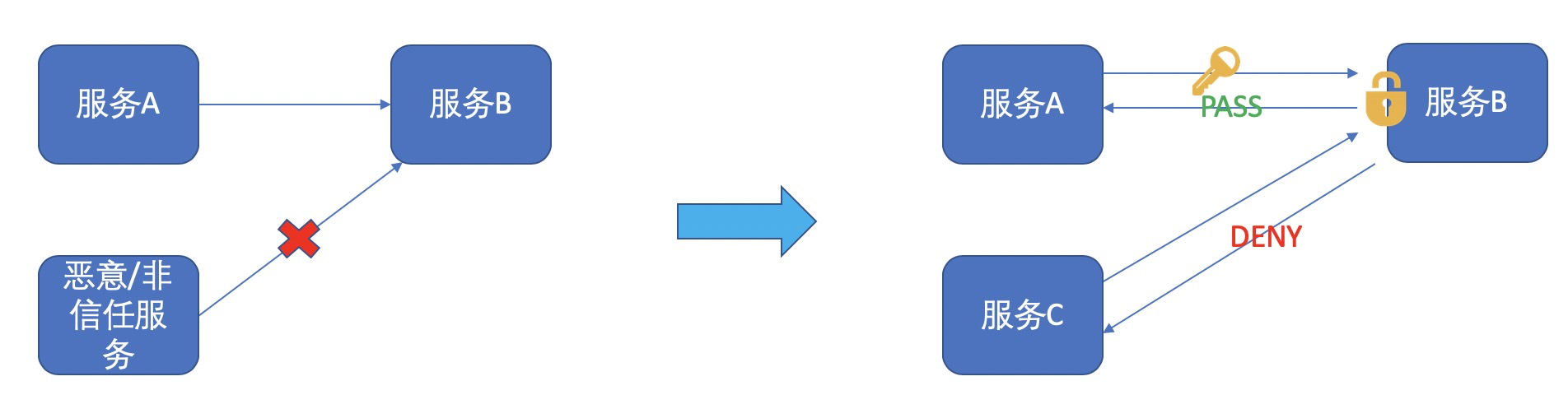
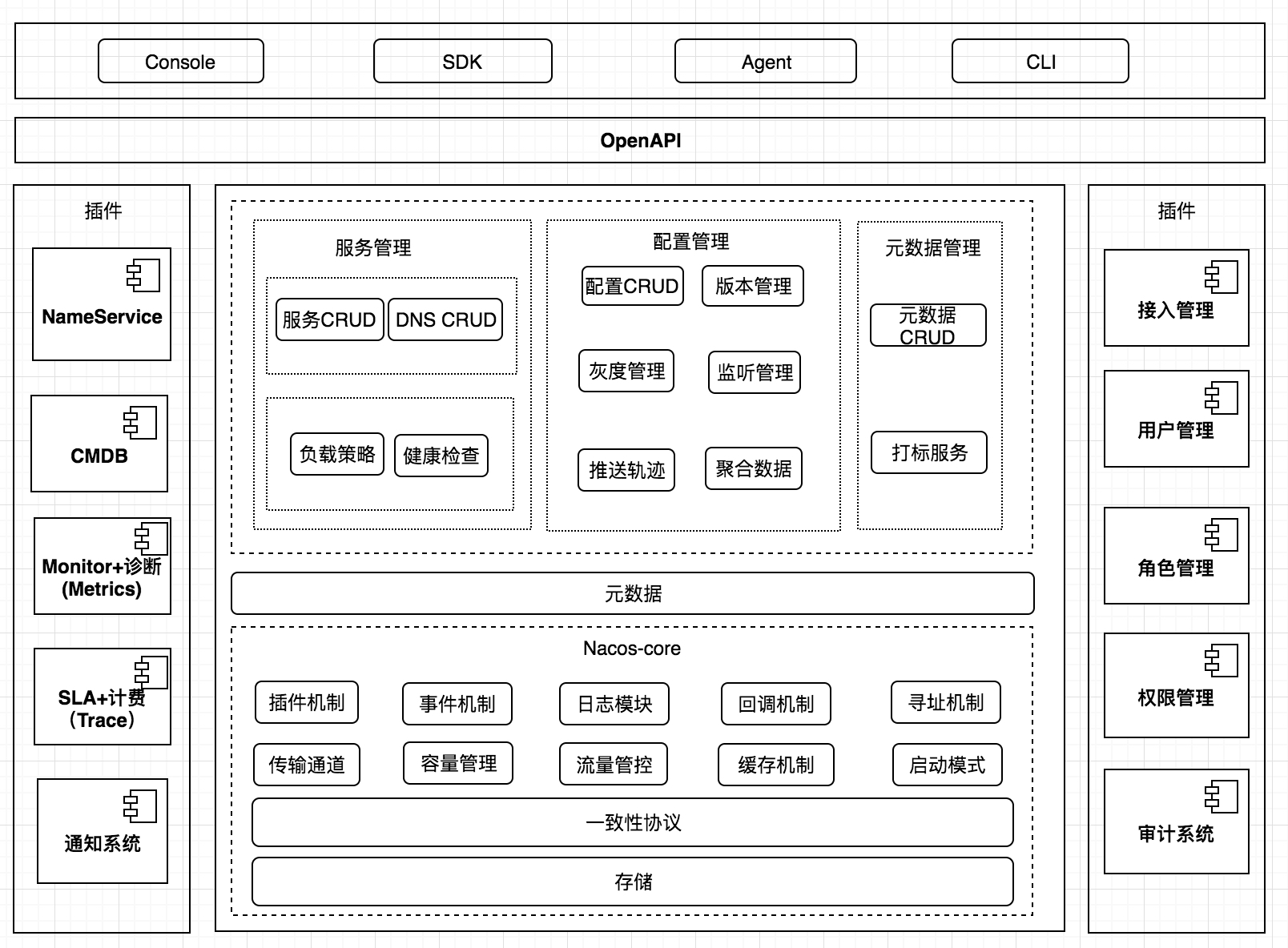
The future overall logical architecture of Nacos and its components
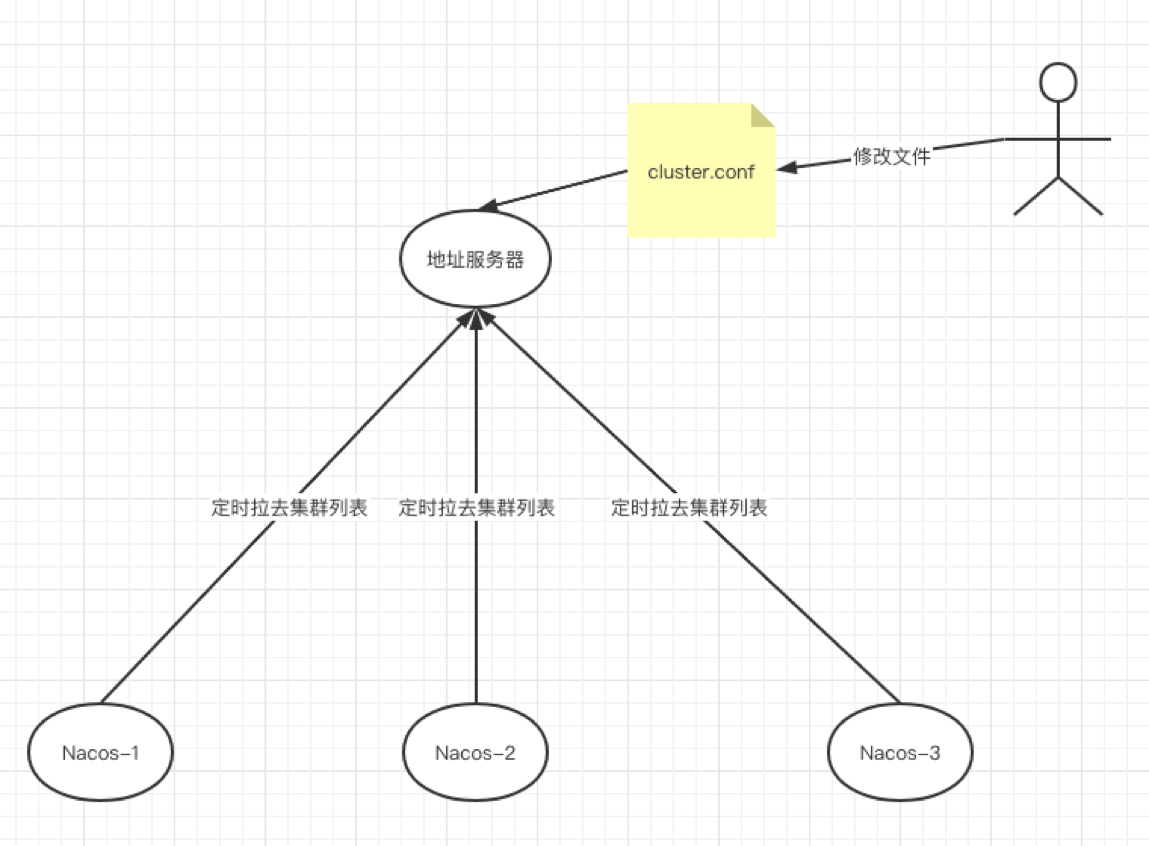
Nacos cluster member node addressing mode
Before 1.3.0, nacos' naming module and config module had their own member list management tasks. In order to unify the replacement mode of nacos assigning the next member list, the implementation of merge management is replaced from the named module and the config module, unified to the addressing module of the core module, and the command line parameters are added at the same time -Dnacos.member.list **To set the list listed by nacos, this parameter can be called an alternative to the cluster.conf file. The current nacos addressing mode categories are as follows
- In stand-alone mode: StandaloneMemberLookup
- Play mode
- The cluster.conf file exists: FileConfigMemberLookup
- The cluster.conf file does not exist or -Dnacos.member.list is not set: AddressServerMemberLookup
If you want to specify an addressing mode, set this parameter:nacos.core.member.lookup.type=[file,address-server]
The logical diagram is as follows

Addressing mode details
Next, I introduce two other addressing modes in addition to the addressing mode in stand-alone mode
FileConfigMemberLookup
This addressing mode is managed based on the cluster.conf file, and each node will read the list of member nodes in the cluster.conf file under their respective ${nacos.home}/conf and then form a cluster. And after reading the cluster.conf file under ${nacos.home}/conf for the first time, it will automatically register a directory listener with the operating system's inotify mechanism to monitor ${nacos.home}/ All file changes in the conf directory (note that only files will be monitored here, and file changes in subdirectories cannot be monitored)
When you need to expand or shrink the cluster nodes, you need to manually modify the content of the member node list of cluster.conf under ${nacos.home}/conf for each node.
private FileWatcher watcher = new FileWatcher() {
@Override
public void onChange(FileChangeEvent event) {
readClusterConfFromDisk();
}
@Override
public boolean interest(String context) {
return StringUtils.contains(context, "cluster.conf");
}
};
@Override
public void start() throws NacosException {
readClusterConfFromDisk();
if (memberManager.getServerList().isEmpty()) {
throw new NacosException(NacosException.SERVER_ERROR,
"Failed to initialize the member node, is empty");
}
// Use the inotify mechanism to monitor file changes and automatically
// trigger the reading of cluster.conf
try {
WatchFileCenter.registerWatcher(ApplicationUtils.getConfFilePath(), watcher);
}
catch (Throwable e) {
Loggers.CLUSTER.error("An exception occurred in the launch file monitor : {}", e);
}
}
The first time you directly read the node list information in the cluster.conf file, then register a directory listener with WatchFileCenter, and automatically trigger readClusterConfFromDisk() to re-read cluster.conf when the cluster.conf file changes file

AddressServerMemberLookup
This addressing mode is based on an additional web server to manage cluster.conf. Each node periodically requests the content of the cluster.conf file from the web server, and then implements addressing between cluster nodes and expansion and contraction.
When you need to expand or shrink the cluster, you only need to modify the cluster.conf file, and then each node will automatically get the latest cluster.conf file content when it requests the address server.
@Override
public void start() throws NacosException {
if (start.compareAndSet(false, true)) {
this.maxFailCount = Integer.parseInt(ApplicationUtils.getProperty("maxHealthCheckFailCount", "12"));
initAddressSys();
run();
}
}
private void initAddressSys() {
String envDomainName = System.getenv("address_server_domain");
if (StringUtils.isBlank(envDomainName)) {
domainName = System.getProperty("address.server.domain", "jmenv.tbsite.net");
} else {
domainName = envDomainName;
}
String envAddressPort = System.getenv("address_server_port");
if (StringUtils.isBlank(envAddressPort)) {
addressPort = System.getProperty("address.server.port", "8080");
} else {
addressPort = envAddressPort;
}
addressUrl = System.getProperty("address.server.url",
ApplicationUtils.getContextPath() + "/" + "serverlist");
addressServerUrl = "http://" + domainName + ":" + addressPort + addressUrl;
envIdUrl = "http://" + domainName + ":" + addressPort + "/env";
Loggers.CORE.info("ServerListService address-server port:" + addressPort);
Loggers.CORE.info("ADDRESS_SERVER_URL:" + addressServerUrl);
}
@SuppressWarnings("PMD.UndefineMagicConstantRule")
private void run() throws NacosException {
// With the address server, you need to perform a synchronous member node pull at startup
// Repeat three times, successfully jump out
boolean success = false;
Throwable ex = null;
int maxRetry = ApplicationUtils.getProperty("nacos.core.address-server.retry", Integer.class, 5);
for (int i = 0; i < maxRetry; i ++) {
try {
syncFromAddressUrl();
success = true;
break;
} catch (Throwable e) {
ex = e;
Loggers.CLUSTER.error("[serverlist] exception, error : {}", ExceptionUtil.getAllExceptionMsg(ex));
}
}
if (!success) {
throw new NacosException(NacosException.SERVER_ERROR, ex);
}
GlobalExecutor.scheduleByCommon(new AddressServerSyncTask(), 5_000L);
}
During initialization, it will take the initiative to synchronize the current cluster member list information with the address server, and if it fails, retry, the maximum number of retries can be controlled by setting nacos.core.address-server.retry, The default is 5 times, and then after success, a scheduled task will be created to synchronize the cluster member node information to the address server
How node management and addressing modes are combined
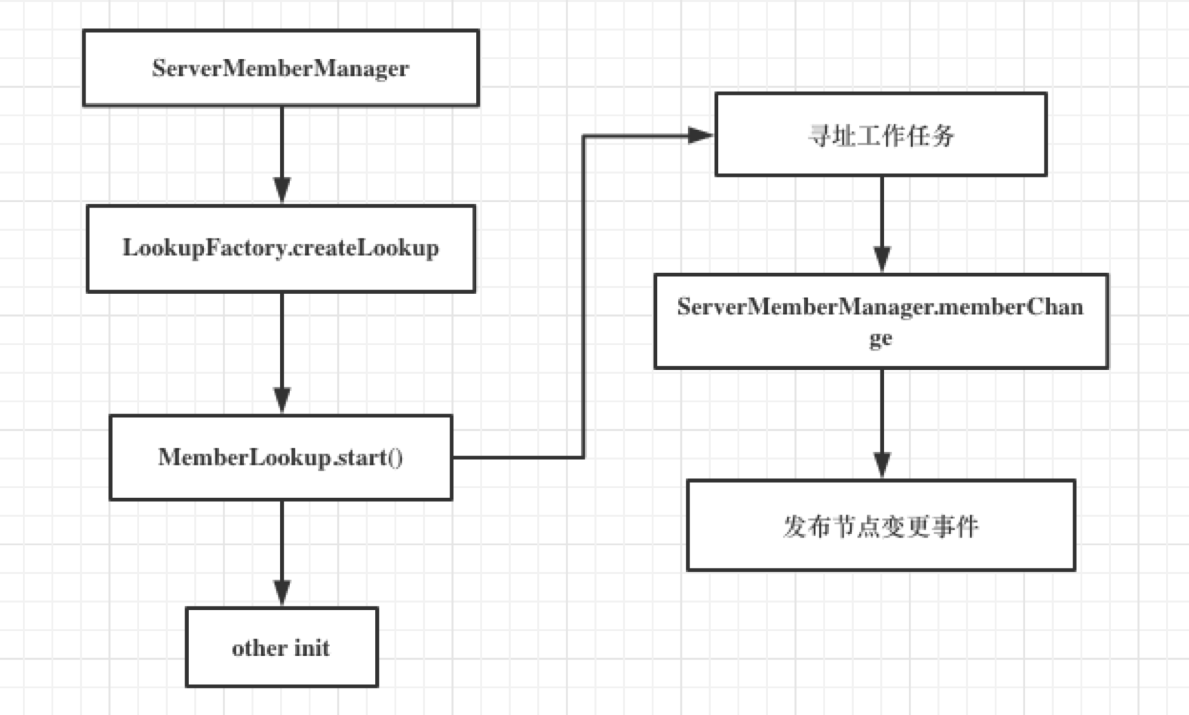
After MemberLookup starts, it will perform addressing tasks according to different addressing modes, will collect cluster node list information, call memberChange, trigger cluster node changes, and then publish node change events
Nacos consensus protocol protocol layer abstraction
From the overall architecture of nacos in the future, it can be seen that the consistency protocol layer will be the core module of nacos, and will serve each functional module built on the core module, or the service and core module itself. The consistency protocol needs to choose between availability and consistency because of the existence of partition fault tolerance, so there are two major types of consistency: final consistency and strong consistency. In nacos, both types of consistency protocols are possible. For example, the naming module uses AP and CP for data management of service instances, respectively. For the config module, it will involve the use of CP. At the same time, there are the following functional demand points
- At present, the persistence service uses a variant version of raft, and the business and the raft protocol are coupled. Therefore, it needs to be decoupled and decoupled. At the same time, a standard Java version of Raft is selected for implementation.
- For small and medium-sized users, the configuration is basically not super much. An independent mysql is relatively heavy and requires a light-weight storage solution. It also supports 2.0 not dependent on mysql and 3.0 dependent on mysql configurability
- Due to CP or AP, there are many implementations, how to make a good abstraction of the consistency protocol layer, so that in the future can quickly achieve the specific implementation of the underlying consistency protocol replacement, such as the Raft protocol, the current selection of nacos It is JRaft, it is not excluded that in the future nacos will implement a standard raft protocol or Paxos protocol by itself
- Since there are multiple function modules working independently in Nacos, there can be no influence between each function module. For example, when the A module processes the request too slowly or an exception occurs, it cannot affect the normal operation of the B module, that is, each function module is in use. How to isolate the data processing of each module when using a consistent protocol?
According to the consensus protocol and the above functional requirements, this time an abstract consensus protocol layer and related interfaces were made
Consensus agreement abstraction
ConsistencyProtocol
The so-called consistency is the characteristic of whether multiple copies can maintain consistency, and the essence of the copy is data, and the operation of the data is either acquisition or modification. At the same time, the consensus protocol is actually for distributed situations, and this necessarily involves multiple nodes. Therefore, there is a need for a corresponding interface to be able to adjust the coordination protocol of the collaborative work node. What if we want to observe the operation of the consistency agreement? For example, the Raft protocol, we want to know who is the leader in the current cluster, the term of office, and who are the member nodes in the current cluster? Therefore, it is also necessary to provide a consistent protocol metadata acquisition.
In summary, the general design of ConsistencyProtcol can come out
public interface ConsistencyProtocol<T extends Config, P extends LogProcessor> extends CommandOperations {
/**
* Consistency protocol initialization: perform initialization operations based on the incoming Config
* 一致性协议初始化,根据 Config 实现类
*
* @param config {@link Config}
*/
void init(T config);
/**
* Add a log handler
*
* @param processors {@link LogProcessor}
*/
void addLogProcessors(Collection<P> processors);
/**
* Copy of metadata information for this consensus protocol
* 该一致性协议的元数据信息
*
* @return metaData {@link ProtocolMetaData}
*/
ProtocolMetaData protocolMetaData();
/**
* Obtain data according to the request
*
* @param request request
* @return data {@link Response}
* @throws Exception
*/
Response getData(GetRequest request) throws Exception;
/**
* Get data asynchronously
*
* @param request request
* @return data {@link CompletableFuture<Response>}
*/
CompletableFuture<Response> aGetData(GetRequest request);
/**
* Data operation, returning submission results synchronously
* 同步数据提交,在 Datum 中已携带相应的数据操作信息
*
* @param data {@link Log}
* @return submit operation result {@link Response}
* @throws Exception
*/
Response submit(Log data) throws Exception;
/**
* Data submission operation, returning submission results asynchronously
* 异步数据提交,在 Datum 中已携带相应的数据操作信息,返回一个Future,自行操作,提交发生的异常会在CompleteFuture中
*
* @param data {@link Log}
* @return {@link CompletableFuture<Response>} submit result
* @throws Exception when submit throw Exception
*/
CompletableFuture<Response> submitAsync(Log data);
/**
* New member list
* 新的成员节点列表,一致性协议自行处理相应的成员节点是加入还是离开
*
* @param addresses [ip:port, ip:port, ...]
*/
void memberChange(Set<String> addresses);
/**
* Consistency agreement service shut down
* 一致性协议服务关闭
*/
void shutdown();
}
For the CP protocol, due to the concept of Leader, it is necessary to provide a method for obtaining who is the current Leader of the CP protocol.
public interface CPProtocol<C extends Config> extends ConsistencyProtocol<C> {
/**
* Returns whether this node is a leader node
*
* @param group business module info
* @return is leader
* @throws Exception
*/
boolean isLeader(String group) throws Exception;
}
Data operation request submission object:Log、GetRequest
As mentioned above, the consistency protocol is actually for data operations. Data operations are basically divided into two categories: data query and data modification, and at the same time, data isolation between different functional modules must be satisfied. Therefore, the data modification operations and data query operations are explained separately here.
- Data modification
- Data modification operation, you must know which functional module this request belongs to
- For data modification operations, you must first know what kind of modification operation this data modification operation is for, so that the function module can perform corresponding logical operations for the real data modification operation
- For data modification operations, you must know what the modified data is, that is, the request body. In order to make the consistency protocol layer more general, here for the data structure of the request body, the byte[] array is selected
- The type of data, because we serialize the real data into a byte[] array, in order to be able to serialize normally, we may also need to record what the type of this data is
- The information summary or identification information of this request
- The additional information for this request is used to expand the data to be transmitted in the future
In summary, it can be concluded that the design of the Log object is as follows
message Log {
// Function module grouping information
string group = 1;
// Abstract or logo
string key = 2;
// Specific request data
bytes data = 3;
// type of data
string type = 4;
// More specific data manipulation
string operation = 5;
// extra information
map<string, string> extendInfo = 6;
}
- Data query
- For data query operations, you must know which function module initiated the request
- What are the conditions for data query? In order to be compatible with data query operations of various storage structures, here byte[] is used for storage
- The additional information for this request is used to expand the data to be transmitted in the future
In summary, the design of the GetRequest object is as follows
message GetRequest {
// Function module grouping information
string group = 1;
// Specific request data
bytes data = 2;
// extra information
map<string, string> extendInfo = 3;
}
Function modules use consistency protocol:LogProcessor
After the data operation is submitted through the consistency protocol, each node needs to process the Log or GetRequest object. Therefore, we need to abstract a Log and GetRequest object Processor. Different functional modules implement the processor. ConsistencyProtocol will internally According to the group attributes of Log and GetRequest, the Log and GetRequest objects are routed to a specific Processor. Of course, the Processor also needs to indicate which functional module it belongs to.
public abstract class LogProcessor {
/**
* get data by key
*
* @param request request {@link GetRequest}
* @return target type data
*/
public abstract Response onRequest(GetRequest request);
/**
* Process Submitted Log
*
* @param log {@link Log}
* @return {@link boolean}
*/
public abstract Response onApply(Log log);
/**
* Irremediable errors that need to trigger business price cuts
*
* @param error {@link Throwable}
*/
public void onError(Throwable error) {
}
/**
* In order for the state machine that handles the transaction to be able to route
* the Log to the correct LogProcessor, the LogProcessor needs to have an identity
* information
*
* @return Business unique identification name
*/
public abstract String group();
}
For the CP protocol, such as the Raft protocol, there is a snapshot design, so we need to separately extend a method for the CP protocol
public abstract class LogProcessor4CP extends LogProcessor {
/**
* Discovery snapshot handler
* It is up to LogProcessor to decide which SnapshotOperate should be loaded and saved by itself
*
* @return {@link List <SnapshotOperate>}
*/
public List<SnapshotOperation> loadSnapshotOperate() {
return Collections.emptyList();
}
}
Summary
As can be seen from the above points, ConsistencyProtocol is the use interface exposed to the upper layer functional modules. Each ConsistencyProtocol has a backend implemented by a specific consistency protocol. Because Backend cannot be well compatible with nacos existing architecture design, so The additional LogProcessor is designed to solve this problem.
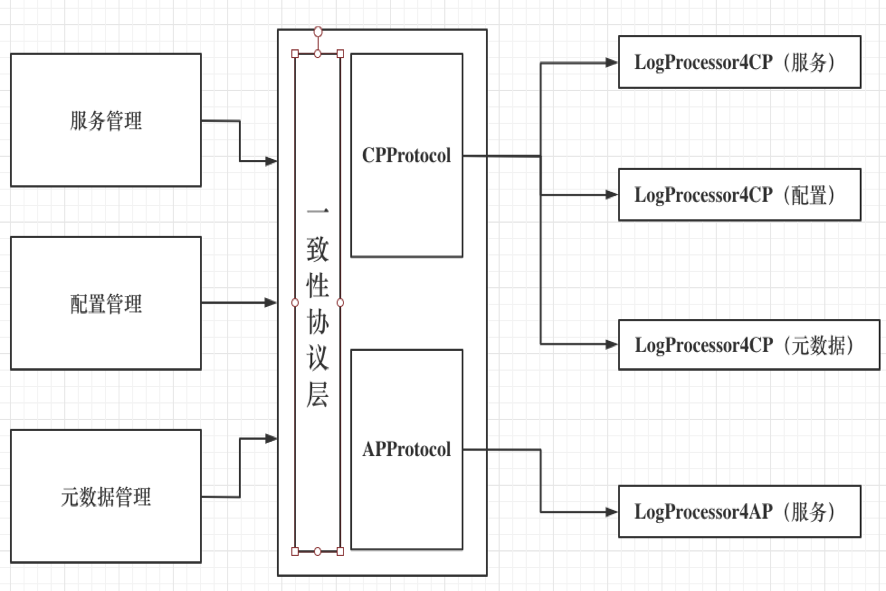
同At the time, because the backend inside the consistency protocol layer needs to implement the isolation processing of the data of different business modules, and this piece of logic is implemented by the request object and the group attribute of the LogProcessor
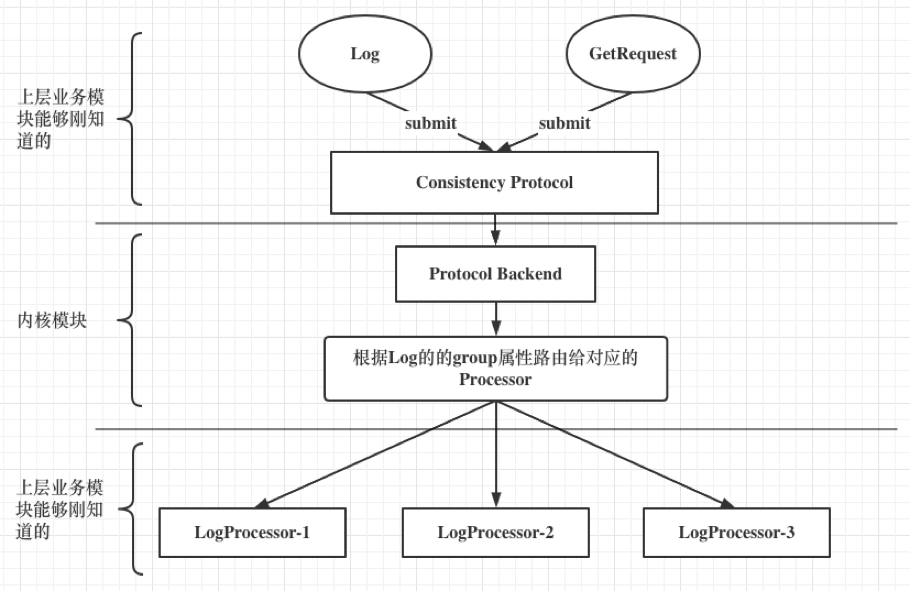
Consistent protocol layer workflow
We can take a look at a sequence diagram, the general workflow of the consistency protocol layer

The implementation option of CP protocol in Nacos consistency protocol layer——JRaft
After the consistency protocol layer is abstracted, the rest is the choice of concrete consistency protocol implementation. Here we have chosen Ant Financial's open source JRaft, so how can we use JRaf as a backend of the CP protocol? The following simple flow chart describes the initialization process when JRaft is used as a Backend of the CP protocol
/**
* A concrete implementation of CP protocol: JRaft
*
* <pre>
* ┌──────────────────────┐
* │ │
* ┌──────────────────────┐ │ ▼
* │ ProtocolManager │ │ ┌───────────────────────────┐
* └──────────────────────┘ │ │for p in [LogProcessor4CP] │
* │ │ └───────────────────────────┘
* ▼ │ │
* ┌──────────────────────────────────┐ │ ▼
* │ discovery LogProcessor4CP │ │ ┌─────────────────┐
* └──────────────────────────────────┘ │ │ get p.group() │
* │ │ └─────────────────┘
* ▼ │ │
* ┌─────────────┐ │ │
* │ RaftConfig │ │ ▼
* └─────────────┘ │ ┌──────────────────────────────┐
* │ │ │ create raft group service │
* ▼ │ └──────────────────────────────┘
* ┌──────────────────┐ │
* │ JRaftProtocol │ │
* └──────────────────┘ │
* │ │
* init() │
* │ │
* ▼ │
* ┌─────────────────┐ │
* │ JRaftServer │ │
* └─────────────────┘ │
* │ │
* │ │
* ▼ │
* ┌────────────────────┐ │
* │JRaftServer.start() │ │
* └────────────────────┘ │
* │ │
* └──────────────────┘
* </pre>
*
* @author <a href="mailto:liaochuntao@live.com">liaochuntao</a>
*/
JRaftProtocol is a concrete implementation of a ConsistencyProtocol when JRaft is used as the backend of the CP protocol. It has a JRaftServer member attribute inside. JRaftServer distributes various API operations of JRaft, such as data operation submission, data query, and member node changes. , Leader node query, etc.
Note: The data generated during JRaft operation is in the ${nacos.home}/data/protocol/raft file directory. Different business modules have different file groupings. If the node crashes or shuts down abnormally, clear the files in the directory and restart the node
Since JRaft implements the concept of raft group, it is possible to use the design of raft group to create a raft group for each function module. Here is part of the code, which shows how to embed LogProcessor in the state machine and create a Raft Group for each LogPrcessor
synchronized void createMultiRaftGroup(Collection<LogProcessor4CP> processors) {
// There is no reason why the LogProcessor cannot be processed because of the synchronization
if (!this.isStarted) {
this.processors.addAll(processors);
return;
}
final String parentPath = Paths
.get(ApplicationUtils.getNacosHome(), "data/protocol/raft").toString();
for (LogProcessor4CP processor : processors) {
final String groupName = processor.group();
if (multiRaftGroup.containsKey(groupName)) {
throw new DuplicateRaftGroupException(groupName);
}
// Ensure that each Raft Group has its own configuration and NodeOptions
Configuration configuration = conf.copy();
NodeOptions copy = nodeOptions.copy();
JRaftUtils.initDirectory(parentPath, groupName, copy);
// Here, the LogProcessor is passed into StateMachine, and when the StateMachine
// triggers onApply, the onApply of the LogProcessor is actually called
NacosStateMachine machine = new NacosStateMachine(this, processor);
copy.setFsm(machine);
copy.setInitialConf(configuration);
// Set snapshot interval, default 1800 seconds
int doSnapshotInterval = ConvertUtils.toInt(raftConfig
.getVal(RaftSysConstants.RAFT_SNAPSHOT_INTERVAL_SECS),
RaftSysConstants.DEFAULT_RAFT_SNAPSHOT_INTERVAL_SECS);
// If the business module does not implement a snapshot processor, cancel the snapshot
doSnapshotInterval = CollectionUtils
.isEmpty(processor.loadSnapshotOperate()) ? 0 : doSnapshotInterval;
copy.setSnapshotIntervalSecs(doSnapshotInterval);
Loggers.RAFT.info("create raft group : {}", groupName);
RaftGroupService raftGroupService = new RaftGroupService(groupName,
localPeerId, copy, rpcServer, true);
// Because RpcServer has been started before, it is not allowed to start again here
Node node = raftGroupService.start(false);
machine.setNode(node);
RouteTable.getInstance().updateConfiguration(groupName, configuration);
RaftExecutor.executeByCommon(() -> registerSelfToCluster(groupName, localPeerId, configuration));
// Turn on the leader auto refresh for this group
Random random = new Random();
long period = nodeOptions.getElectionTimeoutMs() + random.nextInt(5 * 1000);
RaftExecutor.scheduleRaftMemberRefreshJob(() -> refreshRouteTable(groupName),
nodeOptions.getElectionTimeoutMs(), period, TimeUnit.MILLISECONDS);
multiRaftGroup.put(groupName,
new RaftGroupTuple(node, processor, raftGroupService, machine));
}
}
Q&A: Why do you want to create multiple raft groups
Some people may have doubts. Since the LogProcessor has been designed before, you can use a Raft Group. When the state machine is appl, you can route to different LogProcessors according to the Log group attribute. Each function module creates a Raft group, will it consume a lot of resources?
As mentioned before, we hope that the modules that work independently do not affect each other. For example, the A module processing Log may cause the application speed to be slow because of the Block operation, or an exception may occur halfway. For the Raft protocol , When the log apply fails, the state machine will not be able to continue to move forward, because if you continue to move forward, due to the previous step of the apply failure, all subsequent applications may fail, which will cause the data of this node and other nodes Data is never consistent. If we put all the modules that work independently in the same raft group, that is, a state machine, for the data processing request processing, the above-mentioned problems will inevitably occur, and a module will be uncontrollable in the apply log. Factors will affect the normal operation of other modules.
JRaft operation and maintenance
In order to allow users to perform simple operation and maintenance of JRaft, such as leader switching, resetting the current Raft cluster members, triggering a node to perform Snapshot operations, etc., a simple HTTP interface is provided for operation, and the interface has certain Limit, that is, only one operation instruction can be executed at a time
1、Switch the leader node of a certain Raft Group
POST /nacos/v1/core/ops/raft
{
"groupId": "xxx",
"command": "transferLeader"
"value": "ip:{raft_port} or ip:{raft_port},ip:{raft_port},ip:{raft_port}"
}
2、Reset a Raft Group cluster member
POST /nacos/v1/core/ops/raft
{
"groupId": "xxx",
"command": "resetRaftCluster",
"value": "ip:{raft_port},ip:{raft_port},ip:{raft_port},ip:{raft_port}"
}
Note that this operation is a high-risk operation. This operation and maintenance command can only be used when the n/2 + 1 node of the Raft cluster fails to meet the requirements of more than half of the vote after the crash. It is used to quickly reorganize the remaining nodes to the Raft cluster to provide external Service, but this operation will greatly cause the loss of data
3、Trigger a Raft Group to perform a snapshot operation
POST /nacos/v1/core/ops/raft
{
"groupId": "xxx",
"command": "doSnapshot",
"value": "ip:{raft_port}"
}
4、Remove a member of a Raft Group
POST /nacos/v1/core/ops/raft
{
"groupId": "xxx",
"command": "removePeer",
"value": "ip:{raft_port}"
}
5、Remove multiple members of a Raft Group in batches
POST /nacos/v1/core/ops/raft
{
"groupId": "xxx",
"command": "removePeers",
"value": "ip:{raft_port},ip:{raft_port},ip:{raft_port},..."
}
nacos.core.protocol.raft.data.election_timeout_ms=5000
nacos.core.protocol.raft.data.snapshot_interval_secs=30
nacos.core.protocol.raft.data.request_failoverRetries=1
nacos.core.protocol.raft.data.core_thread_num=8
nacos.core.protocol.raft.data.cli_service_thread_num=4
nacos.core.protocol.raft.data.read_index_type=ReadOnlySafe
nacos.core.protocol.raft.data.rpc_request_timeout_ms=5000
Linear reading parameter analysis
- ReadOnlySafe
- In this linear read mode, every time a Follower makes a read request, it needs to synchronize with the Leader to submit the site information, and the Leader needs to initiate a lightweight RPC request to prove that it is the Leader to more than half of the Follower, which is equivalent to a Follower read, at least 1 + (n/2) + 1 RPC request is required.
- ReadOnlyLeaseBased
- In this linear read mode, each time the Follower makes a read request, the Leader only needs to determine whether its Leader lease has expired. If it does not expire, it can directly reply that the Follower is the Leader, but the mechanism has strict requirements on the machine clock. For clock synchronization, consider using this linear read mode.
Nacos embedded distributed ID
The distributed ID embedded in nacos is Snakeflower, the dataCenterId defaults to 1, and the value of workerId is calculated as follows
InetAddress address;
try {
address = InetAddress.getLocalHost();
} catch (final UnknownHostException e) {
throw new IllegalStateException(
"Cannot get LocalHost InetAddress, please check your network!");
}
byte[] ipAddressByteArray = address.getAddress();
workerId = (((ipAddressByteArray[ipAddressByteArray.length - 2] & 0B11)
<< Byte.SIZE) + (ipAddressByteArray[ipAddressByteArray.length - 1]
& 0xFF));
If you need to manually specify dataCenterId and workerId, add command line parameters in application.properties or startup
Nacos embedded lightweight Derby-based distributed relational storage
Background
- If the number of configuration files is small, the cost of supporting a highly available database cluster in the cluster mode is too large, and it is expected to have a lightweight distributed relational storage to solve
- Some metadata information storage inside nacos, such as user information, namespace information
- Source of ideas:https://github.com/rqlite/rqlite
Design ideas
aims
The design goal is to expect nacos to have two data storage modes, one is the current way, the data is stored in an external data source (relational database); the second way is the embedded storage data source (Apache Derby). Users can use the command line parameter configuration to freely use these two data storage modes
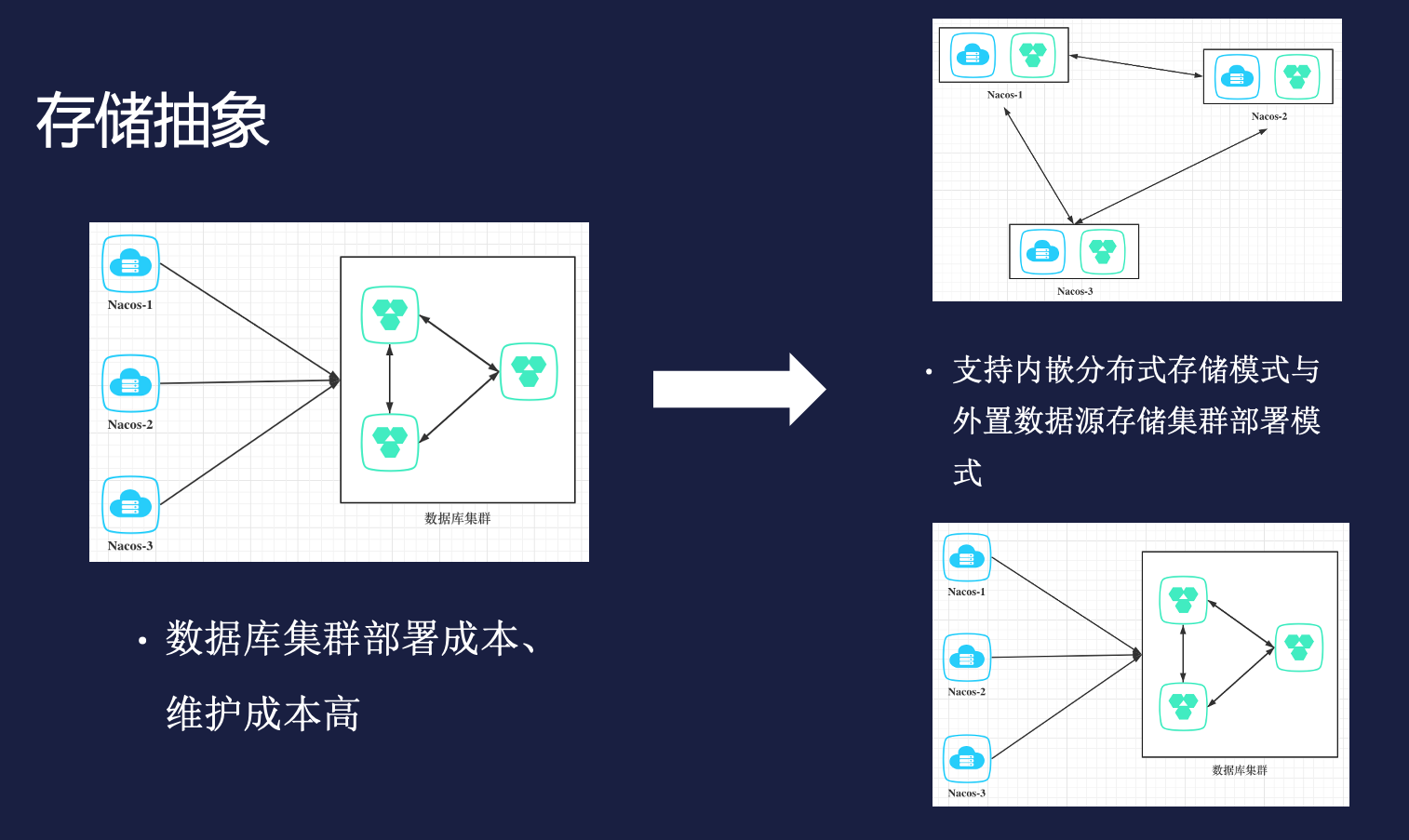
overall
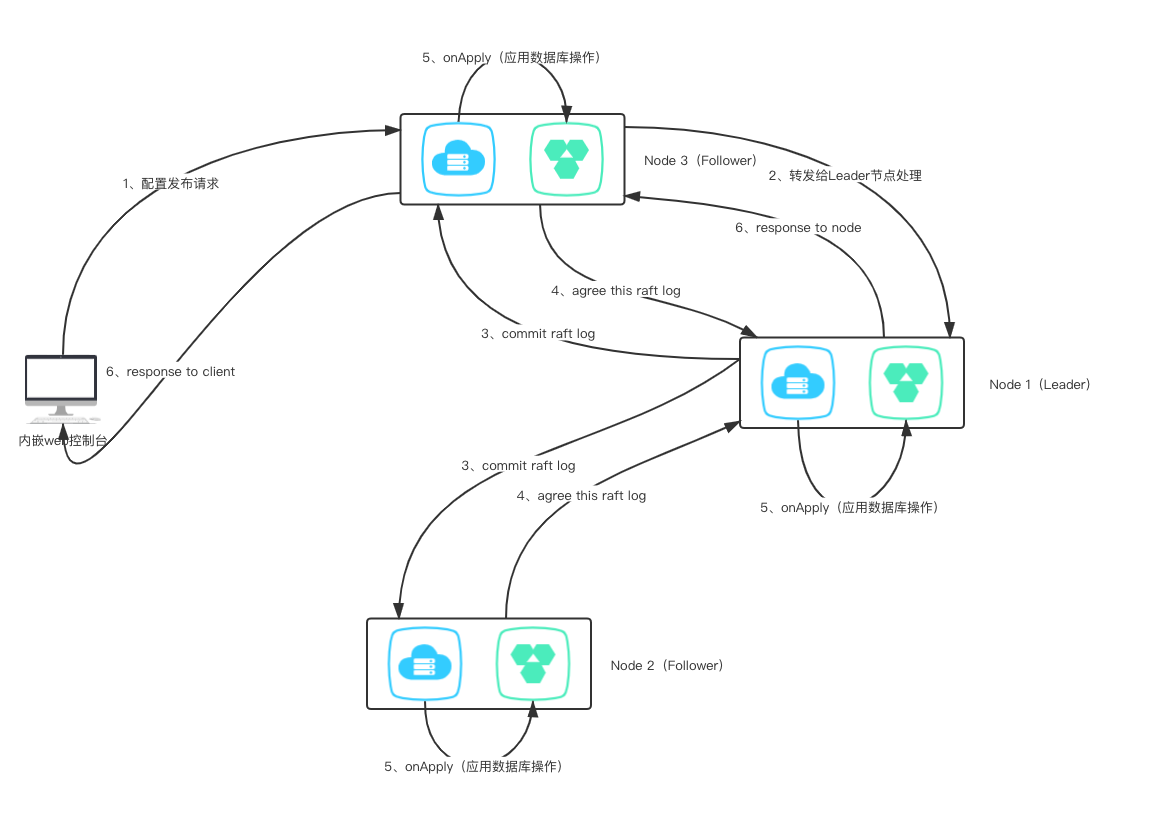
Save the SQL context involved in a request operation in order. Then synchronize the SQL context involved in this request through the consensus protocol layer, and then each node parses it and executes it again in a database session in sequence.
The DML statements of the database are select, insert, update, and delete. According to the nature of SQL statements for data operations, they can be divided into two categories: query and update. The select statement corresponds to data query, and the insert, update, and delete statements correspond to Data modification. At the same time, when performing database operations, in order to avoid SQL injection, PreparedStatement is used, so SQL statements + parameters are required, so two Request objects about database operations can be obtained
- SelectRequest
public class SelectRequest implements Serializable {
private static final long serialVersionUID = 2212052574976898602L;
// Query category, because currently using JdbcTemplate, query a single, multiple queries, whether to use RowMapper into an object
private byte queryType;
// sql语句
// select * from config_info where
private String sql;
private Object[] args;
private String className;
}
- ModifyRequest
public class ModifyRequest implements Serializable {
private static final long serialVersionUID = 4548851816596520564L;
private int executeNo;
private String sql;
private Object[] args;
}
The configuration release operation involves three transactions:
- config_info saves configuration information
- config_tags_relation saves the association relationship between configuration and tags
- his_config_info saves a history of configuration operations
These three transactions are all configured and released under this big transaction. If we say that we perform a Raft protocol submission for each transaction operation, assume that 1, 2 transactions are successfully applied after being submitted through Raft, and the third transaction is in Raft. Apply fails after submission, then for the big transaction released by this configuration, it needs to be rolled back as a whole, otherwise it will violate the atomicity, then it may be necessary to say that the transaction rollback operation is again Raft submitted, then the overall complexity Rise, and directly introduce the management of distributed transactions, so in order to avoid this problem, we integrate the SQL contexts involved in these three transactions into a large SQL context, and submit the Raft protocol to this large SQL context. It ensures that the three sub-transactions successfully solve the atomicity problem in the same database session. At the same time, because the Raft protocol processes the transaction log serially, it is equivalent to adjusting the transaction isolation level of the database to serialization.
public void addConfigInfo(final String srcIp,
final String srcUser, final ConfigInfo configInfo, final Timestamp time,
final Map<String, Object> configAdvanceInfo, final boolean notify) {
try {
final String tenantTmp = StringUtils.isBlank(configInfo.getTenant()) ?
StringUtils.EMPTY :
configInfo.getTenant();
configInfo.setTenant(tenantTmp);
// Obtain the database primary key through the snowflake ID algorithm
long configId = idGeneratorManager.nextId(RESOURCE_CONFIG_INFO_ID);
long hisId = idGeneratorManager.nextId(RESOURCE_CONFIG_HISTORY_ID);
addConfigInfoAtomic(configId, srcIp, srcUser, configInfo, time,
configAdvanceInfo);
String configTags = configAdvanceInfo == null ?
null :
(String) configAdvanceInfo.get("config_tags");
addConfigTagsRelation(configId, configTags, configInfo.getDataId(),
configInfo.getGroup(), configInfo.getTenant());
insertConfigHistoryAtomic(hisId, configInfo, srcIp, srcUser, time, "I");
EmbeddedStorageContextUtils.onModifyConfigInfo(configInfo, srcIp, time);
databaseOperate.blockUpdate();
}
finally {
EmbeddedStorageContextUtils.cleanAllContext();
}
}
public long addConfigInfoAtomic(final long id, final String srcIp,
final String srcUser, final ConfigInfo configInfo, final Timestamp time,
Map<String, Object> configAdvanceInfo) {
...
// 参数处理
...
final String sql =
"INSERT INTO config_info(id, data_id, group_id, tenant_id, app_name, content, md5, src_ip, src_user, gmt_create,"
+ "gmt_modified, c_desc, c_use, effect, type, c_schema) VALUES(?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?)";
final Object[] args = new Object[] { id, configInfo.getDataId(),
configInfo.getGroup(), tenantTmp, appNameTmp, configInfo.getContent(),
md5Tmp, srcIp, srcUser, time, time, desc, use, effect, type, schema, };
SqlContextUtils.addSqlContext(sql, args);
return id;
}
public void addConfigTagRelationAtomic(long configId, String tagName, String dataId,
String group, String tenant) {
final String sql =
"INSERT INTO config_tags_relation(id,tag_name,tag_type,data_id,group_id,tenant_id) "
+ "VALUES(?,?,?,?,?,?)";
final Object[] args = new Object[] { configId, tagName, null, dataId, group,
tenant };
SqlContextUtils.addSqlContext(sql, args);
}
public void insertConfigHistoryAtomic(long configHistoryId, ConfigInfo configInfo,
String srcIp, String srcUser, final Timestamp time, String ops) {
...
// 参数处理
...
final String sql =
"INSERT INTO his_config_info (id,data_id,group_id,tenant_id,app_name,content,md5,"
+ "src_ip,src_user,gmt_modified,op_type) VALUES(?,?,?,?,?,?,?,?,?,?,?)";
final Object[] args = new Object[] { configHistoryId, configInfo.getDataId(),
configInfo.getGroup(), tenantTmp, appNameTmp, configInfo.getContent(),
md5Tmp, srcIp, srcUser, time, ops };
SqlContextUtils.addSqlContext(sql, args);
}
/**
* Temporarily saves all insert, update, and delete statements under
* a transaction in the order in which they occur
*
* @author <a href="mailto:liaochuntao@live.com">liaochuntao</a>
*/
public class SqlContextUtils {
private static final ThreadLocal<ArrayList<ModifyRequest>> SQL_CONTEXT =
ThreadLocal.withInitial(ArrayList::new);
public static void addSqlContext(String sql, Object... args) {
ArrayList<ModifyRequest> requests = SQL_CONTEXT.get();
ModifyRequest context = new ModifyRequest();
context.setExecuteNo(requests.size());
context.setSql(sql);
context.setArgs(args);
requests.add(context);
SQL_CONTEXT.set(requests);
}
public static List<ModifyRequest> getCurrentSqlContext() {
return SQL_CONTEXT.get();
}
public static void cleanCurrentSqlContext() {
SQL_CONTEXT.remove();
}
}
A more intuitive understanding through a timing diagram

How to use new features
Whether to enable the embedded distributed relational storage activity diagram

New features related operation and maintenance operations
Directly query the data stored in each node's derby
GET /nacos/v1/cs/ops/derby?sql=select * from config_info
return List<Map<String, Object>>
insufficient
- Build a distributed data operation synchronization layer on the upper layer of the database, there are restrictions on the operation of the database, such as the first insert operation, then the select operation, and finally the update operation, which is interspersed with query statements in the data modification statement The order of operations is not supported
- Limiting the performance of the database, due to the indirect adjustment of the database transaction isolation level to serialization, the concurrency ability is artificially reduced
Future evolution
Apache Derby official will try to realize the synchronous replication operation of BingLog based on Raft, and realize the database synchronization capability from the bottom