Authors: He Xu
Overview
Nacos is Alibaba's open source project in July 2018 this year,As its name, Naming and Configuration Service ,Focus on service discovery and configuration management。This series of articles,We will fully analyze Nacos from 5W1H(What、Where、When、Who、Why、How),I hope it will be helpful to developers when selecting open source solutions for service discovery and configuration management。
This article serves as the beginning of the Nacos series,Start with "What"。When we started to pay attention to an open source project,Usually the first two questions that come to mind are:
- What is it?
- What problem does it help us to solve?
What is it?
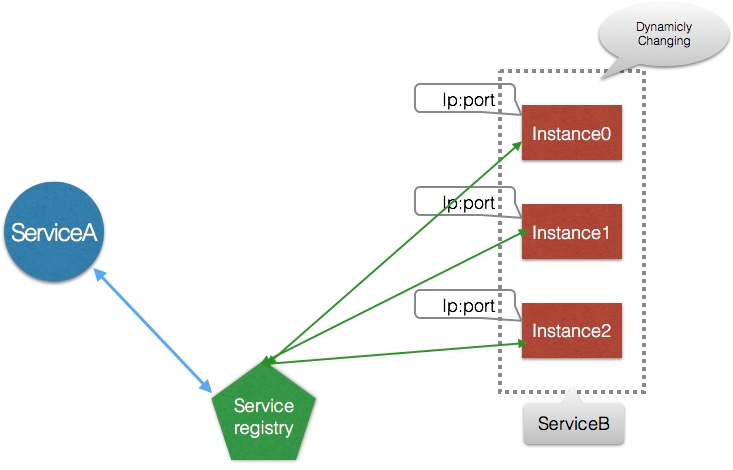
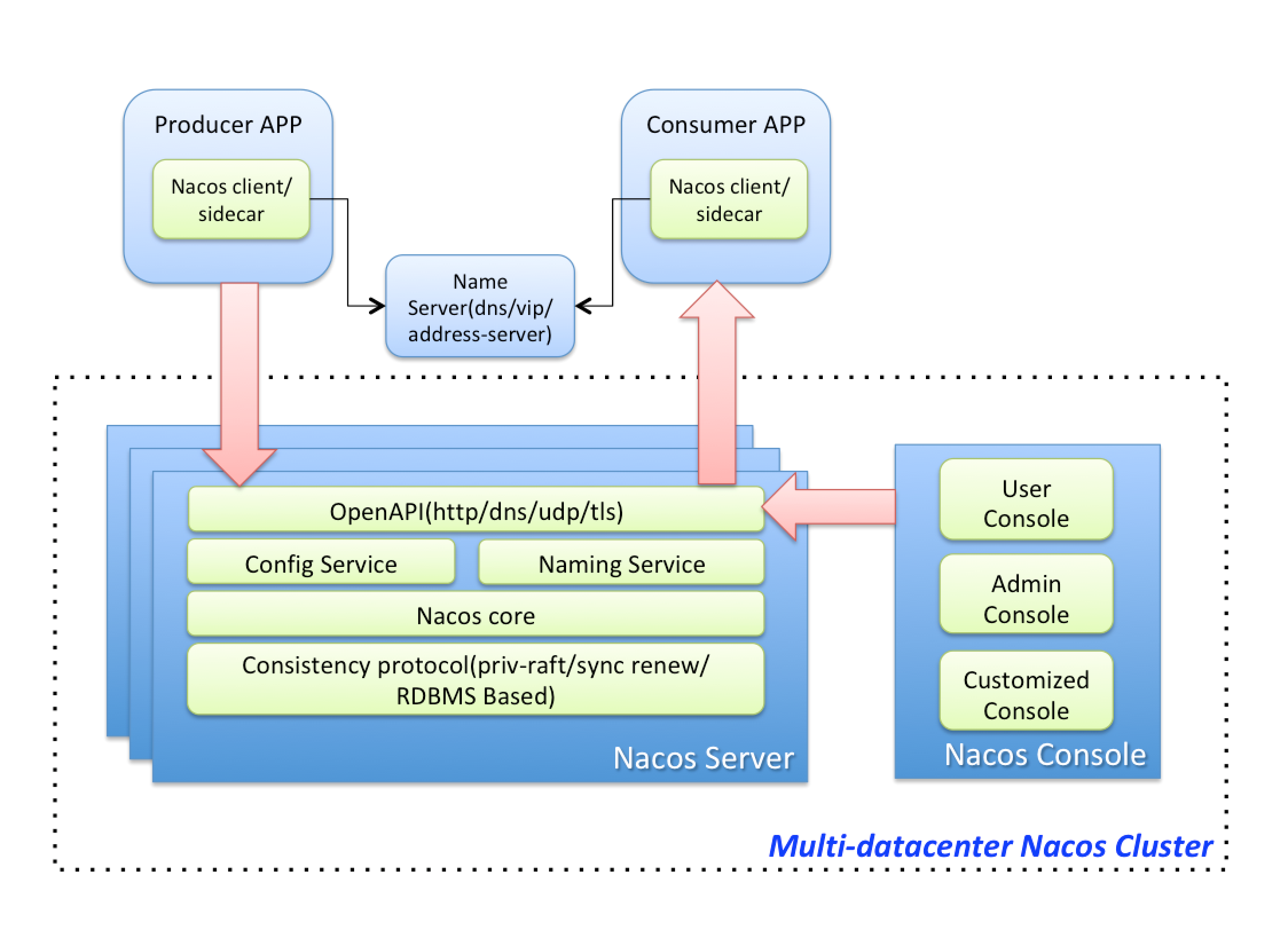
Nacos is a dynamic service discovery, configuration management and service management platform that makes it easier to build Cloud Native applications.
What problem does it help us to solve?
This article will first focus on its "configuration management" function to answer。"Configuration",As a buddy with the code,Accompanied by the entire life cycle of the application,Of course we are also very familiar with it,Think about how many forms of configuration generally exist?
- Hard-Code
- Configuration file
- Database configuration table
Hard-Code
Configuration items exist in the form of class fields. E.g:
public class AppConfig {
private int connectTimeoutInMills = 5000;
public int getConnectTimeoutInMills() {
return connectTimeoutInMills;
}
public void setConnectTimeoutInMills(int connectTimeoutInMills) {
this.connectTimeoutInMills = connectTimeoutInMills;
}
}
There are three main problems with this approach:
If the configuration needs to be modified dynamically,The current application is required to expose the interface for managing the configuration item,As for the Controller's API interface, or JMX, it can be done.
In addition, configuration changes occur in memory and are not persisted.Therefore, restart the application after modifying the configuration, and the configuration will change back to the default value in the code,This is harmful, I have encountered.
Last question,When you have multiple machines,Need to modify a configuration,Every one has to be revised,The cost is very high.
Configuration file
In Spring,properties or ymal or other custom configuration files, such as "conf" suffix:
# application.properties
connectTimeoutInMills=5000
Compared to the "hard-code" form,It solves the second problem,Persistent configuration.However, the other two issues are not resolved,Operation and maintenance costs are still high.
Dynamic configuration changes,It can be through a similar "hard-code" way to expose the management interface,At this time, there will be one more step in the code to persist the logic of the new configuration to the file. Or, simple and rude,Log in to the machine directly to modify the configuration file,And then restart the app,Let the configuration take effect. Of course, you can also add a timing task to the code,For example, read the content of the configuration file every 10s, so that the latest configuration can take effect in the application in time, so that the "heavier" operation and maintenance operation of restarting the application is eliminated.
By adding "persistent logic" and "timed tasks", the form of "configuration files" is a small step forward than "hard-code".
Database configuration table
Database can be a relational database such as MySQL or a non-relational database such as Redis. The data table is as follows:
CREATE TABLE `config` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`key` varchar(50) NOT NULL DEFAULT '' COMMENT '配置项',
`value` varchar(50) NOT NULL DEFAULT '' COMMENT '配置内容',
`updated_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`created_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
UNIQUE KEY `idx_key` (`key`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='配置信息';
INSERT INTO `config` (`key`, `value`, `updated_time`, `created_time`) VALUES ('connectTimeoutInMills', '5000', CURRENT_TIMESTAMP, CURRENT_TIMESTAMP);
Compared with the first two, it takes the configuration a step further, separates the configuration from the application, and centrally manages it, which can greatly reduce the operation and maintenance cost.
So, how can it solve the problem of dynamically updating the configuration? As far as I know, there are two ways。
One,Same as before,Solve by exposing management interface,Of course,Also need to increase the logic of persistence,But before it was to write files, now it is to write the latest configuration to the database. However, the program also needs to periodically read the latest configuration task from the database, so that only by calling the management configuration interface of one of the machines, the latest configuration can be distributed to all the machines in the entire application cluster. Really achieve the purpose of reducing operation and maintenance costs.
Second,Modify the database directly, and read the latest configuration content from the database through timed tasks in the program.
The form of "Database configuration table" solves the main problem, but it is not elegant enough and brings some "cumbersome".
Nacos configuration management
Nacos truly separates the configuration from the application, manages it in a unified way, and elegantly solves the problems of dynamic changes, persistence, operation and maintenance costs of the configuration.
The application itself does not need to add a management configuration interface, nor does it need to implement configuration persistence by itself, and it does not need to introduce "timed tasks" in order to reduce operation and maintenance costs. Nacos The provided configuration management function gathers all the logic related to the configuration, and provides a simple and easy-to-use SDK, so that the configuration of the application can be easily managed by Nacos.
If you are using Nacos in Spring, you only need three steps:
- Add dependency
<dependency>
<groupId>com.alibaba.nacos</groupId>
<artifactId>nacos-spring-context</artifactId>
<version>${latest.version}</version>
</dependency>
- Add
@EnableNacosConfigannotation,Enable Nacos Spring's configuration management service。In the following example, we use@NacosPropertySourceto load the configuration source withdataIdasexampleand enable automatic update:
@Configuration
@EnableNacosConfig(globalProperties = @NacosProperties(serverAddr = "127.0.0.1:8848"))
@NacosPropertySource(dataId = "example", autoRefreshed = true)
public class NacosConfiguration {
}
- Set the attribute value through Spring's
@Valueannotation.
Note: You need to have the Setter method at the same time to automatically update when the configuration changes.
public class AppConfig {
@Value("${connectTimeoutInMills:5000}")
private int connectTimeoutInMills;
public int getConnectTimeoutInMills() {
return connectTimeoutInMills;
}
public void setConnectTimeoutInMills(int connectTimeoutInMills) {
this.connectTimeoutInMills = connectTimeoutInMills;
}
}
The above three steps have almost no code intrusion to the application itself,1 dependency 2 annotations,With just a few lines, the configuration is managed through Nacos.
About the dynamic update of the configuration,For users of Nacos Spring, it is just a boolean value of "autoRefreshed" that is set in their own application。Then when you need to modify the configuration, call Nacos to modify the configuration interface, or use the Nacos console to modify. After the configuration is changed, Nacos will push the latest configuration to all the machines of the application, which is simple and efficient.
Think about it before, in order to realize this function, how much wrong code was written, and how much tedious operation and maintenance work was done. It would be great if you had met Nacos earlier!
Summary
This article serves as the beginning of the Nacos 5W1H series,"What" tells the problem that Nacos configuration management can help us solve: manage configuration in a simple, elegant, and efficient way, realize dynamic configuration changes, greatly reduce operation and maintenance costs, and let developers leave work earlier.
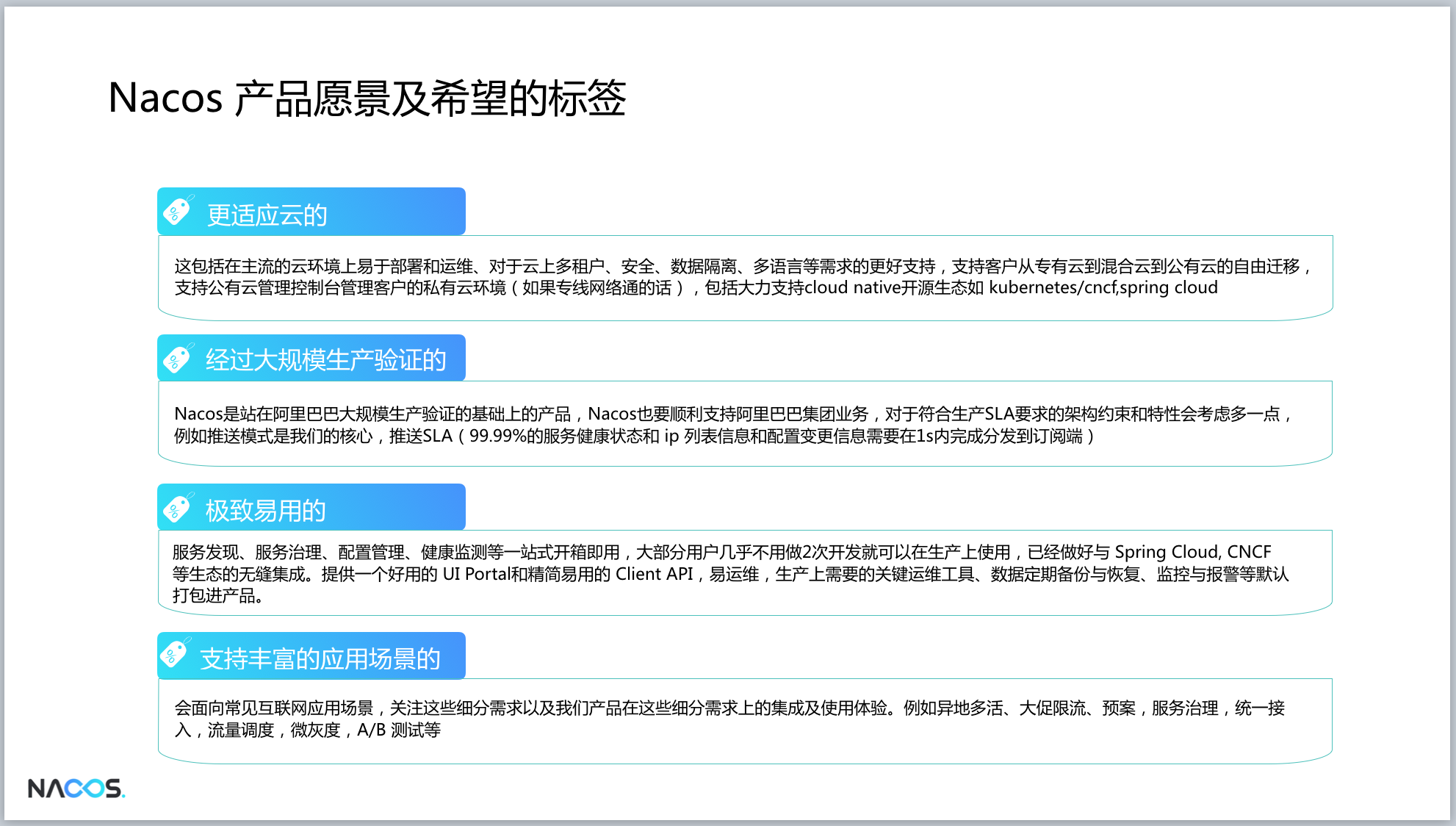
Of course, Nacos configuration management is not only the above-mentioned functions, but also such as "gray release", "version management", "fast rollback", "monitor query", "push trajectory", "authority control", "Encrypted storage of sensitive configuration (eg, database connection configuration)" etc.. Some of these have been implemented in open source in Nacos, and some are provided in the free product of Alibaba Cloud ACM of Nacos configuration management. Of course, the follow-up will be slow Slowly open source to Nacos, so stay tuned.
This series of articles,Will continue to tell everyone about Nacos bit by bit,It's not just about "What problem can Nacos help us solve?",There will also be an in-depth source code analysis "How is Nacos simple and powerful?"。At the same time, if the guys are interested, we will also give you gossip about Nacos' history of barnyard officials, about the history of Nacos in Ali, about the meaning of the Nacos service port, etc.. In short, one sentence: I have a story, and I also have a good wine, what else can you ask for?