
小米Nacos2.0扩缩容最佳实践
一、背景
小米是从1.x版本开始使用Nacos,后来为了性能升级到了2.0.3版本,一直在开启双写的情况下运行稳定,动态的服务发现与分布式配置中心的能力也满足我们的预期,随着使用我们集群的体量越来越大,需要对集群进行扩容,但在实际操作过程中遇到了一些问题,这篇文章主要总结一下集群扩缩容中遇到问题的解决过程和集群扩缩容步骤。
二、集群扩缩容出现的问题
(一) 发现服务降级问题
我们在进行扩容的过程中发现新部署的节点和原有的一个节点的集群管理中的元数据出现了 readyToUpgrade: false,并且经过测试发现这两个节点无法使用2.x版本的SDK进行注册服务,但是可以使用1.x版本的SDK注册,说明原本2.0.3版本的服务端从功能上降级为了1.x版本。
(二) 服务降级的排查过程
查看管理后台集群管理元数据
我们发现在集群管理元数据出现readyToUpgrade: false,通过查看readyToUpgrade相关的源码发现:首次启动时,默认处于未升级状态,此时会开启一个定时任务,检查服务数量与实例数量是否与监控一致,并且是否当前不存在双写任务,如果条件满足则将 readyToUpgrade 字段设置成true,并且通知给其他集群。定时任务会定时判断是否所有实例都满足升级条件,如果满足,则执行升级操作。当我们进行扩容操作的时候,因为新节点刚部署的时候,老节点地址列表没有新节点,新节点是无法完成自动升级的,所以集群管理的节点元数据会出现 readyToUpgrade: false。
查看服务端日志
我们在非新节点的日志文件中发现了服务降级的相关日志。
2022-03-09 17:51:42,262 INFO Downgrade to 1.X根据服务降级日志“Downgrade to 1.X”在代码中全局搜索找到了对应的类UpgradeJudgement。
经过分析UpgradeJudgement源码逻辑,只要满足如下其中一个条件便会出现服务降级:
- 版本信息存在,但是小于2.x。
只有手动通过操作部署低版本节点才可能出现该情况,该设计应该是为了防止升级后的集群有问题需要降级,利用该原理需要降级的时候,只要重新部署一个低版本的节点其他节点可自动降级。
- UpgradeJudgement收到MembersChangeEvent事件,但是member信息中版本为空。
老的版本的集群没有收集节点的版本信息,这里版本为空也降级是为了兼容这部分集群,我们之所以出现意料之外的降级也和这个直接相关。
关键源码:
public void onEvent(MembersChangeEvent event) {
if (!event.hasTriggers()) {
Loggers.SRV_LOG.info("Member change without no trigger. "
+ "It may be triggered by member lookup on startup. "
+ "Skip.");
return;
}
Loggers.SRV_LOG.info("member change, event: {}", event);
for (Member each : event.getTriggers()) {
Object versionStr = each.getExtendVal(MemberMetaDataConstants.VERSION);
// come from below 1.3.0
if (null == versionStr) {
checkAndDowngrade(false);
all20XVersion.set(false);
return;
}
Version version = VersionUtil.parseVersion(versionStr.toString());
if (version.getMajorVersion() < MAJOR_VERSION) {
checkAndDowngrade(version.getMinorVersion() >= MINOR_VERSION);
all20XVersion.set(false);
return;
}
}
all20XVersion.set(true);
}服务降级源码分析
MemberInfoReportTask每隔5秒调用其他节点的/cluster/report 接口上报自己的member数据。
class MemberInfoReportTask extends Task {
private final GenericType<RestResult<String>> reference = new GenericType<RestResult<String>>() { };
private int cursor = 0;
@Override protected void executeBody() { List<Member> members = ServerMemberManager.this.allMembersWithoutSelf();
if (members.isEmpty()) { return; }
this.cursor = (this.cursor + 1) % members.size(); Member target = members.get(cursor);
Loggers.CLUSTER.debug("report the metadata to the node : {}", target.getAddress());
final String url = HttpUtils .buildUrl(false, target.getAddress(), EnvUtil.getContextPath(), Commons.NACOS_CORE_CONTEXT, "/cluster/report");
try { Header header = Header.newInstance().addParam(Constants.NACOS_SERVER_HEADER, VersionUtils.version); AuthHeaderUtil.addIdentityToHeader(header); asyncRestTemplate .post(url, header, Query.EMPTY, getSelf(), reference.getType(), new Callback<String>() { @Override public void onReceive(RestResult<String> result) { if (result.getCode() == HttpStatus.NOT_IMPLEMENTED.value() || result.getCode() == HttpStatus.NOT_FOUND.value()) { Loggers.CLUSTER .warn("{} version is too low, it is recommended to upgrade the version : {}", target, VersionUtils.version); Member memberNew = null; if (target.getExtendVal(MemberMetaDataConstants.VERSION) != null) { memberNew = target.copy(); // Clean up remote version info. // This value may still stay in extend info when remote server has been downgraded to old version. memberNew.delExtendVal(MemberMetaDataConstants.VERSION); memberNew.delExtendVal(MemberMetaDataConstants.READY_TO_UPGRADE); Loggers.CLUSTER.warn("{} : Clean up version info," + " target has been downgrade to old version.", memberNew); } if (target.getAbilities() != null && target.getAbilities().getRemoteAbility() != null && target.getAbilities() .getRemoteAbility().isSupportRemoteConnection()) { if (memberNew == null) { memberNew = target.copy(); } memberNew.getAbilities().getRemoteAbility().setSupportRemoteConnection(false); Loggers.CLUSTER .warn("{} : Clear support remote connection flag,target may rollback version ", memberNew); } if (memberNew != null) { update(memberNew); } return; } if (result.ok()) { MemberUtil.onSuccess(ServerMemberManager.this, target); } else { Loggers.CLUSTER.warn("failed to report new info to target node : {}, result : {}", target.getAddress(), result); MemberUtil.onFail(ServerMemberManager.this, target); } }
@Override public void onError(Throwable throwable) { Loggers.CLUSTER.error("failed to report new info to target node : {}, error : {}", target.getAddress(), ExceptionUtil.getAllExceptionMsg(throwable)); MemberUtil.onFail(ServerMemberManager.this, target, throwable); }
@Override public void onCancel() {
} }); } catch (Throwable ex) { Loggers.CLUSTER.error("failed to report new info to target node : {}, error : {}", target.getAddress(), ExceptionUtil.getAllExceptionMsg(ex)); } }
@Override protected void after() { GlobalExecutor.scheduleByCommon(this, 2_000L); } }当调用失败时会执行MemberUtil的onFail方法
public static void onFail(final ServerMemberManager manager, final Member member, Throwable ex) { manager.getMemberAddressInfos().remove(member.getAddress()); final NodeState old = member.getState(); member.setState(NodeState.SUSPICIOUS); member.setFailAccessCnt(member.getFailAccessCnt() + 1); int maxFailAccessCnt = EnvUtil.getProperty(MEMBER_FAIL_ACCESS_CNT_PROPERTY, Integer.class, DEFAULT_MEMBER_FAIL_ACCESS_CNT);
// If the number of consecutive failures to access the target node reaches // a maximum, or the link request is rejected, the state is directly down if (member.getFailAccessCnt() > maxFailAccessCnt || StringUtils .containsIgnoreCase(ex.getMessage(), TARGET_MEMBER_CONNECT_REFUSE_ERRMSG)) { member.setState(NodeState.DOWN); } if (!Objects.equals(old, member.getState())) { manager.notifyMemberChange(member); } }在onFail方法中,会判断节点状态是否发生了改变,比如由UP变为SUSPICIOUS,如果发生了改变,则会执行manager.notifyMemberChange(member)。在前面复现降级的场景下,存在一个节点宕机,所以重启的节点report宕机节点时一定会触发MemberUtil的onFail方法的执行,而当前重启的节点持有的宕机节点状态默认是UP,当执行onFail时,会变成SUSPICIOUS,所以会执行manager.notifyMemberChange(member),发布MembersChangeEvent事件,由于这个事件是由宕机节点触发的,所以MembersChangeEvent事件中trigger的member版本号为null,UpgradeJudgement收到MembersChangeEvent事件,并且member信息中版本为空,根据第2点的结论,此时会触发当前节点降级
void notifyMemberChange(Member member) { NotifyCenter.publishEvent(MembersChangeEvent.builder().trigger(member).members(allMembers()).build());}服务降级过程时序图
为了方便理解,画了如下简单的时序图,省略了一些return和异步执行
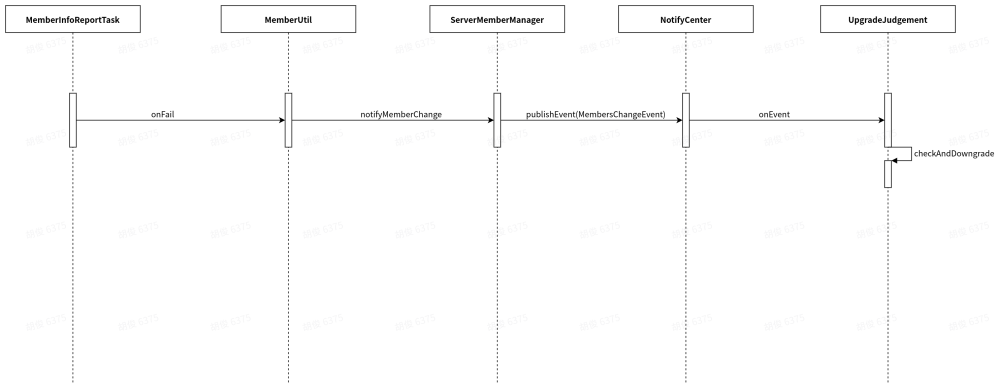
为什么关闭双写后服务不会降级
前面已经提到,降级的必要条件是UpgradeJudgement收到MembersChangeEvent,关闭双写后,UpgradeJudgement会取消订阅MembersChangeEvent,并且将双写是否关闭的值通过jraft写入到磁盘,当服务启动时又会重新加载到内存从而取消订阅MembersChangeEvent。
private class DoubleWriteEnabledChecker extends Thread {
private volatile boolean stillCheck = true;
@Override public void run() { Loggers.SRV_LOG.info("Check whether close double write"); while (stillCheck) { try { TimeUnit.SECONDS.sleep(5); stopDoubleWrite = !ApplicationUtils.getBean(SwitchDomain.class).isDoubleWriteEnabled(); if (stopDoubleWrite) { upgradeJudgement.stopAll(); stillCheck = false; } } catch (Exception e) { Loggers.SRV_LOG.error("Close double write failed ", e); } } Loggers.SRV_LOG.info("Check double write closed"); } }本地复现服务降级
在本地以2.0.3版本启动三个节点(node1、node2、node3)的集群模式,等三个节点都运行稳定后,查看其中每个节点数据目录(${nacos.home}/data/upgrade.state)下的升级状态都为true,说明三个节点目前都是2.x版本的状态。此时关闭node3节点,重启node1节点,启动完成后,发现node1此时会发生服务降级。
服务降级排查结论
在2.0.3版本默认开启双写,只要nacos集群其中一个节点挂掉,剩余节点如果不将这个节点从地址列表中移除,只要重启便会出现服务降级;另外在并发部署的情况下,也有可能出现服务降级。 关闭双写会关闭运行中服务降级的入口,所以2.x服务运行稳定后一定要关闭双写,我们的服务之所以会降级也是因为运行后未关闭双写。
(三) 临时解决方案
由于我们的Nacos集群已经正常升级到了2.0.3,并且稳定运行了一段时间,已经有很多客户端在使用2.x的版本,节点出现降级会导致这部分客户端无法进行注册,所以无论在任何情况下,都不能出现服务降级,决定执行如下方案:
- 扩容时新节点启动完成后关闭双写,强制新节点升级到2.x版本。
- 暂时先将服务降级的方法代码逻辑删除,只打印日志。 代码改动如下:
private void checkAndDowngrade(boolean jraftFeature) {
Loggers.SRV_LOG.info("jraftFeature:{} ignore Downgrade to 1.X", jraftFeature);
}(四) 社区解决方案
我们将服务降级的问题也反馈给Nacos PMC席翁,在社区Nacos2.1.0正式版中,已经默认关闭了兼容 1.X 服务端升级,所以只要不手动开启,2.x的Nacos不可能在出现服务降级的问题,后续我们也会逐步将所有共有集群升级到2.1.0版本。
关闭兼容1.x服务端升级的功能对应PR:https://github.com/alibaba/nacos/pull/8016
三、集群扩缩容推荐
扩缩容使用的运维接口
关闭双写 :
/nacos/v1/ns/operator/switchesentry=doubleWriteEnabled&value=false查看节点监控:
/nacos/v1/ns/upgrade/ops/metrics(一) 集群扩容操作步骤
- 部署新节点。
- 关闭新节点双写,检查日志是否出现如下日志,如果naming-raft出现了如下日志,说明降级入口已自动关闭。
start to close old raft protocol!!!- 通过metrics接口查看双写是否关闭成功
- 手动修改老节点集群配置文件 cluster.conf,无须重启。
- 使用metrics接口查看新节点数据是否与老节点一致。
- 测试新节点服务注册与发现,配置添加与查询等基本功能是否正常。
(二) 集群缩容操作步骤
- nginx 去掉待移除节点ip。
- 修改保留节点集群配置文件cluster.conf,无须重启,等待所有节点数据一致。
- 观察nginx日志,确保移除merger节点无流量。
- top待移除节点,检查保留节点状态,模拟注册验证。
若是操作机器降配,需要先停服,再停机器,不然可能出现raft数据压缩包有问题的情况。
(三) 扩缩容优化点
目前我们每次进行扩缩容都需要修改每个节点的cluster.conf文件,操作非常繁琐,其实nacos提供了nacos-address 组件,引入nacos-address组件后进行扩缩容时无须一台一台修改地址,只需要修改Nacos-adress服务中的地址即可,可大大提升扩缩容效率。
四、总结
1.x版本升级到2.1.0之前的版本并且运行稳定后,必须关闭双写。
新集群统一使用2.1.0版本进行部署,否则在一定的场景下可能出现服务降级导致部分节点不可用。
对于体量较大的集群,需要引入nacos-address组件管理集群节点,避免手动频繁手动修改文件导致的误操作提升扩缩容效率。